AI-Compliant Validation Processes
Ensuring Compliance and Efficiency

Introduction
The increasing integration of artificial intelligence (AI) into business processes offers financial institutions significant opportunities and potential, while at the same time presenting them with new challenges. At the latest since the EBA discussion paper on the use of machine learning for IRB models in model validation, it has become clear that supervisory authorities are also increasingly considering the use of AI in risk modeling. While the productive use of AI models is still viewed with some caution, the EBA explicitly recommends the use of AI as a challenger model in validation.
Traditional validation approaches are designed for classical statistical models and have so far only taken limited account of the use of AI. In order to address the growing regulatory and technological trend, we recommend deploying validation strategies in a targeted manner to assess and control classical models more efficiently and more comprehensively.
In this article, we explain how an enhanced validation process using AI models can be designed, which best practices from classical methods should be retained, and which new approaches are required to address the specific challenges of AI models. Particular focus is placed on the core elements of the validation process.
A well-structured AI validation process enables firms to use AI models efficiently, transparently, and in compliance with applicable requirements, while at the same time minimizing model risk and meeting regulatory expectations.
Enhanced Validation Process for AI Models
Steps in the Validation Process
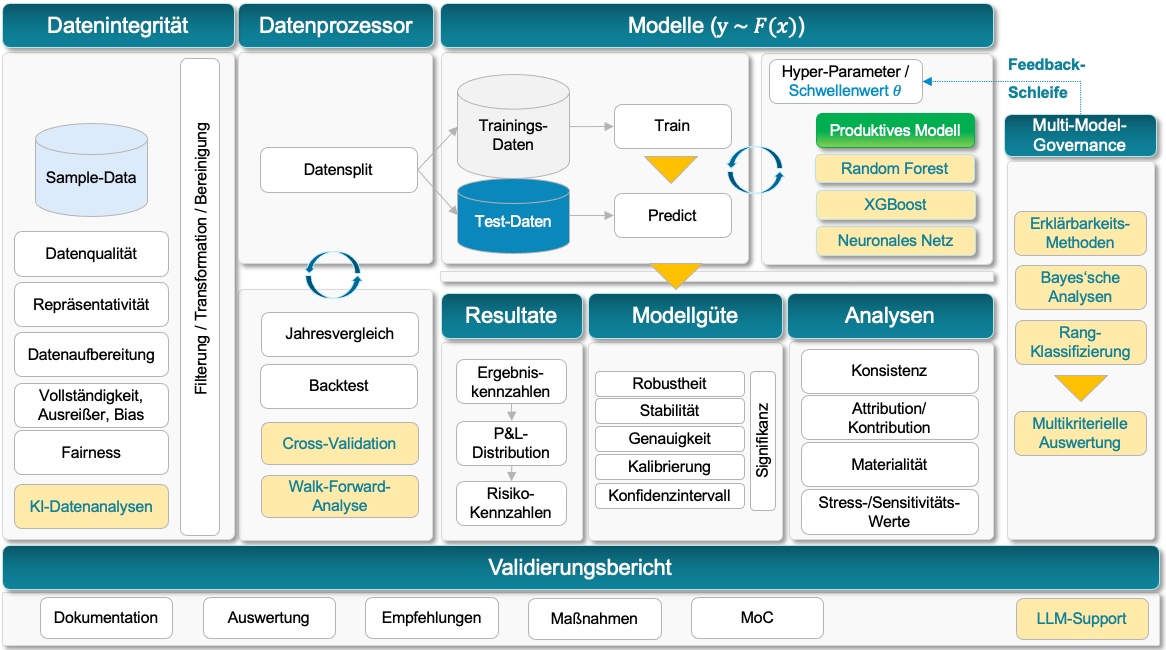
This step is intended to ensure that the data used for both the productive model and the challenger model are consistent and unbiased. In addition to classical methods, modern AI approaches enable initial scanning and continuous monitoring of data. Automated ongoing monitoring features used to assess adherence to assumptions are becoming increasingly common, even without AI. Nevertheless, modern machine learning methods offer expanded capabilities, especially in the context of large data volumes, complex data flows, and nested system landscapes.
Monitoring approaches:
- Drift Monitoring: Monitoring changes in input data and their relationship to the target variable. Two main types are distinguished:
- Feature Drift: A change in the distribution of input features over time, for example changes in the income distribution of borrowers.
- Concept Drift: A change in the relationship between input data and the target variable, for example where rising interest rates lead to higher default probabilities even among borrowers with strong income profiles.
- Statistical Methods: Established methods for identifying differences between data sets and distributions, such as:
- Kolmogorov-Smirnov-Test: Tests whether two probability distributions differ significantly.
- Jensen-Shannon Divergence: Measures the similarity between two probability distributions.
- Wasserstein Distance: Determines the minimum effort required to transform one probability distribution into another.
- Comparison with Reference Data: Continuous comparison of new data with the original training data.
- Threshold Breach Alerts: Automatic notifications when significant changes occur.
Traditional validation methods such as backtesting and year-on-year comparisons are frequently used. However, for AI-based models these methods are often insufficient, as such models generally require more data and more specific validation techniques. One established method is cross-validation, which enables a robust assessment of model performance by using the available data efficiently.
Cross-Validation
Cross-validation is an essential technique in machine learning for assessing a model’s ability to generalize. Compared with classical backtesting approaches, it uses the available data more efficiently. While backtesting typically uses only a single train-test data set, cross-validation allows for a more robust and comprehensive assessment.
Examples:
- K-Fold-Cross-Validation: The data are divided into K equally sized subsets (folds). The model is trained K times, each time using a different fold as the test set while the remaining folds are used for training.
- Leave-One-Out-Cross-Validation (LOOCV): Each individual data point serves once as the test set, while all other data points are used for training. This approach is particularly useful for small data sets.
- Stratified Cross-Validation: Similar to K-Fold, but the distribution of the target variable is taken into account in each fold to ensure that all classes are proportionally represented. For example, this ensures that each fold contains a sufficient number of credit defaults and prevents extreme cases in which a fold contains no defaults at all.
- Time-Series Cross-Validation: For time-dependent data, cross-validation is adapted so that future values are never used to predict the past, thereby producing more realistic results. In this context, walk-forward-analysis is particularly relevant. This is a validation method specifically designed for time-dependent data, such as financial markets or credit histories. It is frequently used in algorithmic modeling and risk management to assess the temporal stability of a model.
In addition to the productive model, AI-based challenger models are developed in order to compare their performance and robustness. This enables continuous improvement and helps ensure that the optimal model remains in productive use.
In the diagram above, several AI challenger models are shown alongside the productive model. These models use the same data input in order to ensure a consistent basis for comparison. The AI challenger models are trained using modern algorithms, such as neural networks, gradient boosting decision trees, random forests, and others. Using the same underlying data makes it possible to evaluate differences in model architecture and performance objectively. Classical challenger models, such as Monte Carlo simulation and finite-difference methods, may also form part of the model portfolio.
The purpose of challenger models is not to replace the productive model. Rather, they serve primarily as tools for validation and benchmarking, helping to identify weaknesses in the productive model and to provide a benchmark for possible optimization.
The challenge lies in evaluating the resulting volume of multi-criteria outcomes in an appropriate way and deriving well-founded recommendations and decisions from them. For this purpose, a multi-model governance framework should be designed and integrated, which we address in the next section.
4) Multi-Model Governance:
A Framework for the Multi-Criteria Evaluation of the Model Portfolio
Back to diagram
The comparison between the productive model and one or more AI challenger models poses a structural and decision-theoretical challenge due to the large number of results involved, including ambiguous findings, across k algorithms and n data sets.
Managing multiple models requires clear rules and processes to ensure consistency and compliance. An effective multi-model Governance framework helps define responsibilities and manage the model life cycle.
Feedback Loops for the Continuous Improvement of the Productive Model
Multi-model governance also defines which types of results are taken into account, how they are consolidated and evaluated, and how recommendations and actions can be derived from them in order to improve the productive model continuously. This is achieved in particular through the integration of insights from challenger models in the form of feedback loops, which play a central role in the validation process.
Collection and Analysis of Results:
Performance, stability, and drift analyses are systematically performed, documented, and assessed for both the productive model and the challenger models.
Deriving Insights:
It is analyzed which areas of the productive model, such as specific data segments or scenarios, can be improved. For example, features that are better used or modeled in the challenger model can reveal weaknesses in the productive model.
Model Adjustment:
Insights from the challenger analyses are incorporated into the parameterization of the productive model. This includes:
-
- Fine-tuning thresholds or risk add-ons.
- Improving the model structure, for example by adjusting categories or incorporating new factors.
- Integrating outputs from challenger models as additional input factors.
Re-evaluierung:
Validation is carried out to determine whether the adjustments made achieve the desired improvements. Ongoing comparison with challenger models ensures that the changes are effective and that new insights are taken into account.
Über die Feedback-Schleife hinaus sollte die Multi-Model-Governance auch die folgenden drei Aspekte berücksichtigen, die schlussendlich zu der Multikriteriellen Auswertung führen:Beyond the feedback loop, multi-model governance should also take into account the following three aspects, which ultimately lead to the multi-criteria evaluation:
Explainability Methods
To increase transparency and comparability across models, model-agnostic analyses are used, such as:
-
- SHAP (Shapley Additive Explanations) and LIME (Local Interpretable Model-agnostic Explanations): For detailed analysis of the contribution of individual features.
- Scatterplots and P&L Comparisons: To visualize performance.
- Error and Loss Analyses: To highlight differences at event level.
These methods create a common basis for evaluation and transparency by making models interpretable both globally and locally.
Bayesian Analysen
ROPE analysis (Region of Practical Equivalence) enables pairwise comparison of models based on relevant differences in model quality metrics, for example AUC, Brier score, and similar measures. Differences below a threshold, such as 0.01, are considered immaterial. Relevant differences are attributed to one model or the other depending on direction, in order to demonstrate model dominance where such differences occur in a high proportion of cases, for example 95%. This analysis shows whether two models are practically equivalent. It does not make a statement about statistical significance.
Rank-Based Classifications
Significant differences between two models, in the sense of a p-test, can be examined using the following approaches.
Friedman Test and Nemenyi Test:
We consider k models across n data sets. The Friedman test can be used to test the models for significant differences between algorithms on the basis of an applied metric, such as AUC, Gini, or Brier score. If the Friedman test shows that differences exist, it does not indicate which algorithms differ significantly. Der Nemenyi test is then used as a post hoc test to conduct pairwise comparisons between algorithms. It shows whether two models differ significantly.
As an alternative to the Friedman test, an ANOVA test could also be used. However, for this purpose the comparison data should be normally distributed and independent.
The integration of large language models (LLMs) into the validation process opens up innovative possibilities for analyzing, structuring, and leveraging results. LLMs can help interpret complex data and models, derive valid conclusions, and create reports efficiently. In particular, within the context of multi-model governance , the use of LLMs enables a systematic and traceable summary of insights from meta-comparisons and validation processes.
Through automation, improved communication, and interactive analysis, LLMs can significantly enhance the efficiency and quality of validation reports. Extensions such as dashboards, regulatory-compliant reporting, and narrative evaluations make the integration of LLMs a forward-looking approach in the banking environment.
Potential Use Cases for LLMs in Validation Reporting:
Automated Report Generation: LLMs can transform validation outcomes, such as performance comparisons, drift monitoring, and SHAP analyses, into understandable reports.
Explanation and Visualization: LLMs can explain complex model decisions and deviations in natural language.
Anomaly Detection and Assessment: LLMs can identify unusual patterns in the data or results and propose how they should be interpreted or remediated.
Scenario Analysis and Recommended Actions: LLMs can evaluate the outcomes of scenario analyses, for example under stress conditions, and derive concrete recommendations.
Overview of Multi-Model Governance: LLMs can generate governance-compliant documentation based on the results of multi-model analysis, such as model rankings, Bayesian analyses, and stability assessments.
Interactive Dashboards with LLM Integration: Combination of LLMs with interactive dashboards to enable users to analyze scenarios and results dynamically.
Regulatory-Compliant Summaries: LLMs can structure reports in line with the requirements of supervisory authorities, such as BaFin or the ECB.
Stakeholder Communication: LLMs can tailor reports for different stakeholders, for example technical detail for data scientists and regulatory overviews for senior management.
Narrative Evaluation of Model Alternatives: LLMs can generate narrative text that presents complex comparisons, for example between productive and challenger models, in an understandable way.
While classical validation approaches provide a solid foundation, they increasingly reach their limits when it comes to incorporating AI-supported risk models. The integration of AI-based challenger models opens up entirely new potential for extending and optimizing existing validation processes, making them more efficient, more precise, and more dynamic.
✅ Enhanced Pattern Recognition
AI can identify complex relationships in the data that remain hidden from classical models. This enables a deeper analysis of model assumptions and helps detect potential weaknesses at an early stage.
✅ Dynamic Monitoring and Drift Detection
AI models enable continuous monitoring of model performance in real time. Especially in rapidly changing market conditions, AI can help identify concept drift or feature drift at an early stage and initiate countermeasures.
✅ Automated Validation Processes
Many time-consuming validation steps, such as sensitivity analyses, scenario analyses, or report generation, can be significantly accelerated and standardized through AI-supported automation. This not only increases efficiency but also reduces human sources of error.
✅ Intelligent Challenger Approaches
AI-based challenger models go beyond classical review and enable the active enhancement of existing approaches. Through adaptive learning methods, they can help develop more robust and resilient models.
However, an AI-compliant validation process requires new methodological frameworks in order to appropriately address regulation, transparency, and model risk. In a subsequent article, using credit scoring models as an example, we will show how AI challenger models can be used to support the continuous improvement of the productive model.
As a specialized consulting firm, we support banks in the regulatory-compliant implementation of ML models, from strategy development through to sustainable integration into existing processes.
Would you like to learn more about AI-supported model validation? Contact us for a non-binding consultation